
- 邮箱:
- 广东省广州市天河区88号
- 电话:
- /public/upload/system/2018/07/26/f743a52e720d8579f61650d7ca7a63a0.jpg
- 传真:
- /public/upload/system/2018/07/26/fe272790a21a4d3e1e670f37534a3a7d.png
- 手机:
- 13800000000
- 地址:
- 1234567890
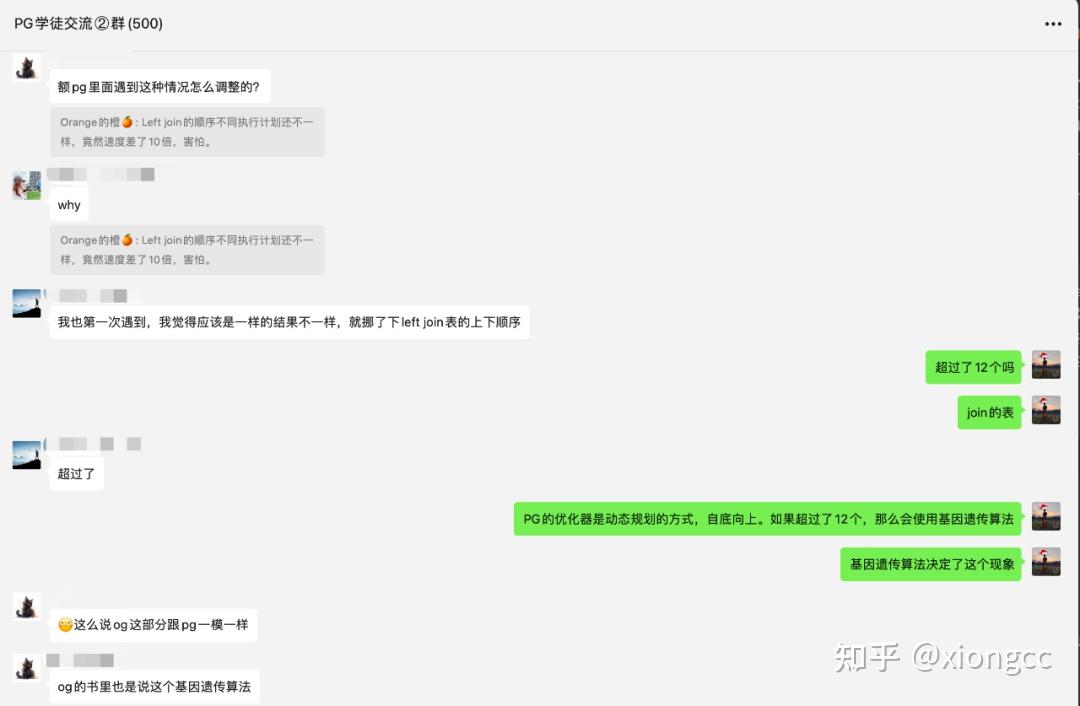
今天下午帮同事处理了一个关于优化器的案例,赶巧②群也有位老铁提了这样一个问题
Left join 的顺序不同执行计划还不一样,竟然速度差了10倍,害怕。
群友纷纷表示不可思议,其实这是个正常的现象,也借此机会,与各位再好好唠唠 PostgreSQL 强大的优化器。
数据库路径的搜索方法通常有3种类型:自底向上方法、自顶向下方法、随机方法,而 PostgreSQL 采用了其中的两种方法:自底向上和随机方法,其中自底向上的方法是采用动态规划方法,而随机方法采用的是遗传算法,对于连接比较少的情况使用动态规划,否则使用遗传算法。
动态规划采用自底向上算法,也就是经典的穷举算法,"动态规划"将待求解的问题分解为若干个子问题 (子阶段),按顺序求解子问题,前一子问题的解为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个子问题就是初始问题的解,十分枯燥,看得头都大了。
让我们看个栗子:
- 比如现在有个 SQL 是 select * from a where id=10,那么首先全表扫描肯定可以,然后去获取统计信息估算出相应的代价;假如 id 列有索引,那么再去估算索引扫描的代价;先为基表确定扫描路径,估计扫描路径的代价和大小。
- 假如现在的 SQL 变复杂了,需要 join:select * from a join b on (a.id=b.id) where a.id>10;,那么现在就要考虑更多了,假如使用 nestloop,看看 join 能不能用上索引,被驱动表上有没有索引,估计其代价,hash join、merge join 也是类似,看看能不能将某个表物化成 hash table,merge join 要求数据先排序,那么看看有没有索引能消除 SORT 算子诸如此类;最终把这些可能的 join 方式全部列出来,然后分别计划其代价,筛选出代价最低的路径,现在我们就得到了两个表 join 的最优解。
- 那假如现在又多了一个表,通过前两步骤,现在已知{A B}、{A C}、{B C}这三种 JOIN 的最优解,开始求解三张表的最优解,分别求解{A B}JOIN C、{A C}JOIN B、{B C}JOIN A 这三种 JOIN 的代价,得到代价最小的路径
- ...
假如是 5 个表?10 个表?那么最终就会依次穷举 A ? B、A ? C、A ? D、B ? C...,N 个表的连接,理论上有 N! 个不同的连接顺序;不难想象,随着参与 JOIN 的表数量增加,要穷举的数量也会线性递增,因此动态规划适合查询中包含的表较少的情况。

$ SELECT i, (i)! AS num_comparisons FROM generate_series(8, 20) i;
i | num_comparisons
----+---------------------
8 | 40320
9 | 362880
10 | 3628800
11 | 39916800
12 | 479001600
13 | 6227020800
14 | 87178291200
15 | 1307674368000
16 | 20922789888000
17 | 355687428096000
18 | 6402373705728000
19 | 121645100408832000
20 | 2432902008176640000
(13 rows)假如现在有个实际查询长这样:SELECT * FROM A JOIN (B JOIN C ON B.j=C.j) ON A.i=B.i; 经过一系列复杂算法,最终生成的路径可能长这样 :
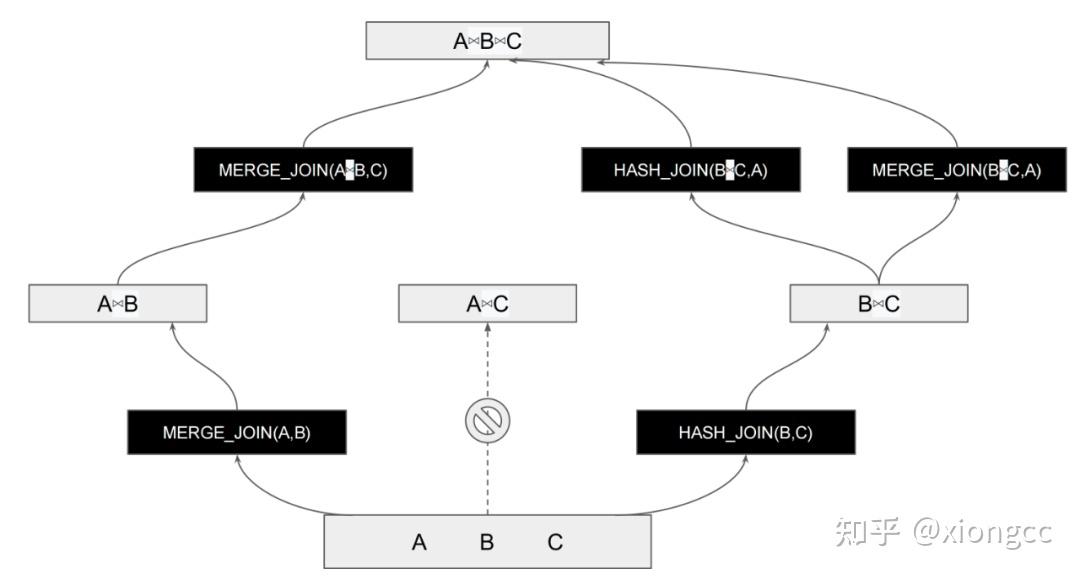
当然 PostgreSQL 优化器还会使用启发式算法,一个基于直观或经验构造的算法,在可接受的花费 (指计算时间、占用空间等) 下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度不一定事先可以预计。
在 PostgreSQL 的逻辑查询优化阶段和物理查询优化阶段,都有一些启发规则可用,举几个大白话例子:
- 比如对于不存在连接条件的两个表,尽量不做连接
- A 连接 B,其中一个关系上的连接列存在索引,则采用索引连接且此关系作为内表
- A 连接 B,其中一个关系上的连接列是排序的,则采用排序进行连接比哈希连接好
- 最小的表或者集合"先行"
- 选择率或者 WHERE 子句最有效的表"先行"
- ...
至于逻辑优化阶段使用的启发式规则通常包括比如子查询消除 (把子查询提升到父查询之中,就可以使子查询参与整个计划搜索空间,从而找到更好的执行计划)、条件化简 (比如函数内联、简化常量表达式) 等。
可以看到,随着表数量的上涨,再穷举所有可能的路径是不现实的,因此 PostgreSQL 还使用了基因遗传算法。
else
{
......
// 如果有自定义join生成算法则使用
if (join_search_hook)
return (*join_search_hook) (root, levels_needed, initial_rels);
// 如果开启了遗传算法且join关系大于阈值(默认12)则使用遗传算法
else if (enable_geqo && levels_needed >= geqo_threshold)
return geqo(root, levels_needed, initial_rels);
else // 否则,使用动态规划算法
return standard_join_search(root, levels_needed, initial_rels);
}
}一旦超过了阈值 (geqo_threshold=12),PostgreSQL 就会采用基因遗传算法,开始时,遗传优化器会生成一组随机计划。然后对这些计划进行检查。效果不好的被丢弃,新计划基于好计划的基因生成。这样,有可能生成更好的计划。这个过程可以根据需要重复多次。但是其缺点便是得到局部最优解,并非全局最优解。
所以根据经验,我也直接问了 2 群这位朋友:join 的表超过了12 个吗?果然得到了这样的答复。
另外一个不得不提的参数是 join_collapse_limit,用于控制 JOIN 是否重写到 FROM 列表中。官网的注释各位可能看的云里雾里:
The planner will rewrite explicitJOINconstructs (exceptFULL JOINs) into lists ofFROMitems whenever a list of no more than this many items would result. Smaller values reduce planning time but might yield inferior query plans.
By default, this variable is set the same asfrom_collapse_limit, which is appropriate for most uses. Setting it to 1 prevents any reordering of explicitJOINs. Thus, the explicit join order specified in the query will be the actual order in which the relations are joined. Because the query planner does not always choose the optimal join order, advanced users can elect to temporarily set this variable to 1, and then specify the join order they desire explicitly. For more information see Section 14.3.
Setting this value to geqo_threshold or more may trigger use of the GEQO planner, resulting in non-optimal plans. See Section 20.7.3.
就以官网的例子为例
SELECT * FROM a, b, c WHERE a.id = b.id AND b.ref = c.id;优化器可以按照任何顺序连接。例如,
- 可以生成一个使用
WHERE条件a.id=b.id连接 A 到 B 的查询计划,然后用另外一个WHERE条件把 C 连接到这个连接表。 - 可以先连接 B 和 C 然后再连接 A 得到同样的结果。
- 或者也可以连接 A 到 C 然后把结果与 B 连接 — 不过这么做效率不好,因为必须生成完整的 A 和 C 的迪卡尔积,而在
WHERE子句中没有可用条件来优化该连接,虽然语义是相同的,但是执行开销上却有巨大差别。
显式连接语法(INNER JOIN、CROSS JOIN或无修饰的JOIN)在语义上和FROM中列出输入关系是一样的, 因此并不约束连接顺序。
SELECT * FROM a, b, c WHERE a.id = b.id AND b.ref = c.id;
SELECT * FROM a CROSS JOIN b CROSS JOIN c WHERE a.id = b.id AND b.ref = c.id;
SELECT * FROM a JOIN (b JOIN c ON (b.ref = c.id)) ON (a.id = b.id);但是如果我们显式告诉优化器 JOIN 的顺序,那么第二个和第三个会比第一个在规划上的时间要少,对于只有少数表的 JOIN 可能微不足道,但是!正如我前所说的,随着你表数量的增加,这笔开销就会很可观,可能就是你的救命稻草了。这个时候要强制规划器遵循显式JOIN的连接顺序, 我们就可以把 join_collapse_limit 设置为 1。
SELECT * FROM a CROSS JOIN b, c, d, e WHERE ...;比如这样一个查询,就先强制 A 连接 B,再去连接其他表,这样可能连接顺序的量就减少了 5 倍,如果是默认值,那么总的连接顺序是 5!=120 种,而设置为了 1,一旦 a 和 b 被连接,它们就被视为一个单独的实体,随后的连接就不再考虑改变 a 和 b 之间的连接顺序。在这种情况下,可能的连接顺序数目就变成了 4!(即 4 的阶乘),因为我们已经将 a 和 b 视为一个单一实体。所以,总的可能连接顺序数是 4 × 3 × 2 × 1=24 种。
假设现在有 ABCD 四个表关联,你将 join_collapse_limit 设置为 2,那么
- 优化器可能会考虑连接 A 和 B,C 和 D,然后再连接这两组的结果。
- 优化器也许会考虑其他的连接组合,比如先连接 A 和 C,然后 B 和 D,然后再将结果组合起来。
即 (这种大白话各位应该能看懂了!)
- [a, b],[a, c],[a, d],[b, c],[b, d],[c, d]
- [[a, b], c],[[a, b], d],[[a, c], b],[[a, c], d],[[a, d], b],[[a, d], c],[[b,c], a],[[b, c], d],[[b, d], a],[[b, d], c],[[c, d], a],[[c, d], b]
- [[[a, b], c], d],[[[a, b], d], c],[[[a, c], b], d],[[[a, c], d], b],[[[a, d],b], c],[[[a, d], c], b],[[[b, c], a], d],[[[b, c], d], a],[[[b, d], a], c],[[[b, d], c], a],[[[c, d], a], b],[[[c, d], b], a]
这种方法减少了优化器需要考虑的连接组合的数量,从而节省了规划时间。
要观察的话,可以使用这个例子,然后将 join_collapse_limit 设置为不同的值。
test=# EXPLAIN WITH x AS
(
SELECT *
FROM generate_series(1, 1000) AS id
)
SELECT *
FROM x AS a
JOIN x AS b ON (a.id = b.id)
JOIN x AS c ON (b.id = c.id)
JOIN x AS d ON (c.id = d.id)
JOIN x AS e ON (d.id = e.id)
JOIN x AS f ON (e.id = f.id)另外还有一个类似的 from_collapse_limit,效果类似。
以上就是关于优化器的一些底层知识了,下期让我们再聊聊 Dark side of optimizer。
https://leovan.me/cn/2019/04/heuristic-algorithms/
Master PostgreSQL 11


