
- 邮箱:
- 广东省广州市天河区88号
- 电话:
- /public/upload/system/2018/07/26/f743a52e720d8579f61650d7ca7a63a0.jpg
- 传真:
- /public/upload/system/2018/07/26/fe272790a21a4d3e1e670f37534a3a7d.png
- 手机:
- 13800000000
- 地址:
- 1234567890
优化代码布局(code layout) 是一项对于性能提升的重要优化,目前在编译时和链接时都有对应可行的优化手段。而 BOLT(Binary Optimization and Layout Tool) 则是链接后优化(post-link optimizer),使用基于采样的 profile 信息,甚至可以对已经进行过 FDO(feedback-driven optimization) 和 LTO(link-time optimization) 之后的二进制,再次提升其运行性能,所以这是一个可作为补充的优化手段。根据论文中测试数据,在 FDO 和 LTO 基础上,提升了 GCC 和 Clang 编译器 20.4% 的性能。还可以用来优化没有源码的第三方库。
BOLT 是 facebook 推出的优化工具,目前 BOLT 已经合进去 LLVM 仓库作为一部分,具体使用有官方文档,不展开介绍了。
对于以数据中心驱动的应用而言,提升代码的局部性是优化性能的关键。FDO,也可称之为 PGO(profile-guided optimization,之前写过关于 Instrumentation 的文章,可以翻翻)。instrumentation-based PGO 在插桩(probe) 收集 profile 信息阶段会带来巨大的内存和性能消耗,其复杂的操作流程也导致其难以施行。所以 BOLT 采取 sampling-based PGO 的方式,使用诸如 perf 工具进行数据采样,减少了方案实行的复杂度,同时也减少了内存与性能消耗。
而且 BOLT 是在对链接后的二进制层面做优化,相对于 PGO 在编译期和链接期的机器码生成之前阶段的操作,也会更加简单,和 LTO 同样拥有整个程序的全局视角来做优化。因为要优化代码布局,在低层级(low-level) 优化中,sampling-based PGO 的 profile 信息也是基于二进制层面的,准确度和匹配程度也会更高。所以即使经过 LTO 和 PGO 的优化,BOLT 的优势就在于在二进制层面还有优化空间,而且 profile 的准确度和匹配程度也较高。准确度和匹配程度是很重要的,因为使用不准确的 profile 甚至可能会导致性能倒退,而不匹配的 profile 则会导致错失一些优化机会。

BOLT 会跳过那些它无法处理的函数,比如比较复杂的还未支持的函数、无法重建 CFG(control-flow graph,控制流图) 的函数。而且可能会带来代码体积的增加,因为 cold paths(执行频次较小的路径) 的 branch(分支跳转) 会变多(基于 profile 可以判断 cold code,通常会被转移到其他地方,所以需要添加跳转执行的指令,这样也有效地提升内存使用率);而且 x86 架构的 conditional branch(条件分支跳转) 指令有个特点,带符号偏移量(signed offset) 如果只用 8-bit 会需要 2-bytes,而如果要用 32-bit 则需要 6-bytes。

因为是在二进制层面进行代码布局优化操作,定位函数位置就比较重要了。BFD 和 Gold 链接器提供了 --emit-relocs 参数输出重定位信息。虽然存在一些信息丢失,如同一编译单元的内部函数引用的定位信息丢失,可以通过反汇编来检测和修复。有了重定位信息,辅以 ELF 文件对应的符号表(symbol table) 和栈信息(frame information、从汇编中以及 DWARF(一种标准化的调试信息的存储格式) 的 CFI(Call Frame Information) 中可以获取函数信息),对于重新进行代码的布局就很好控制了,可以在二进制层面很好地重排函数的顺序、切分函数的实现。但由于链接器的数量众多,所以 BOLT 没有把实现耦合到链接器当中,而是实现了一个独立的 post-link optimizer(链接后优化器)。
BOLT 使用了 LLVM 来处理反汇编、构建 CFG、对二进制文件的修改、解析函数和内部符号(如 basic block 也是)的引用关系。BOLT 同时也会使用 profile 信息进行数据流分析,实际上除了优化代码布局,还有很多 pass 可以执行(下图是以 Intel x86-64 中的情况)。
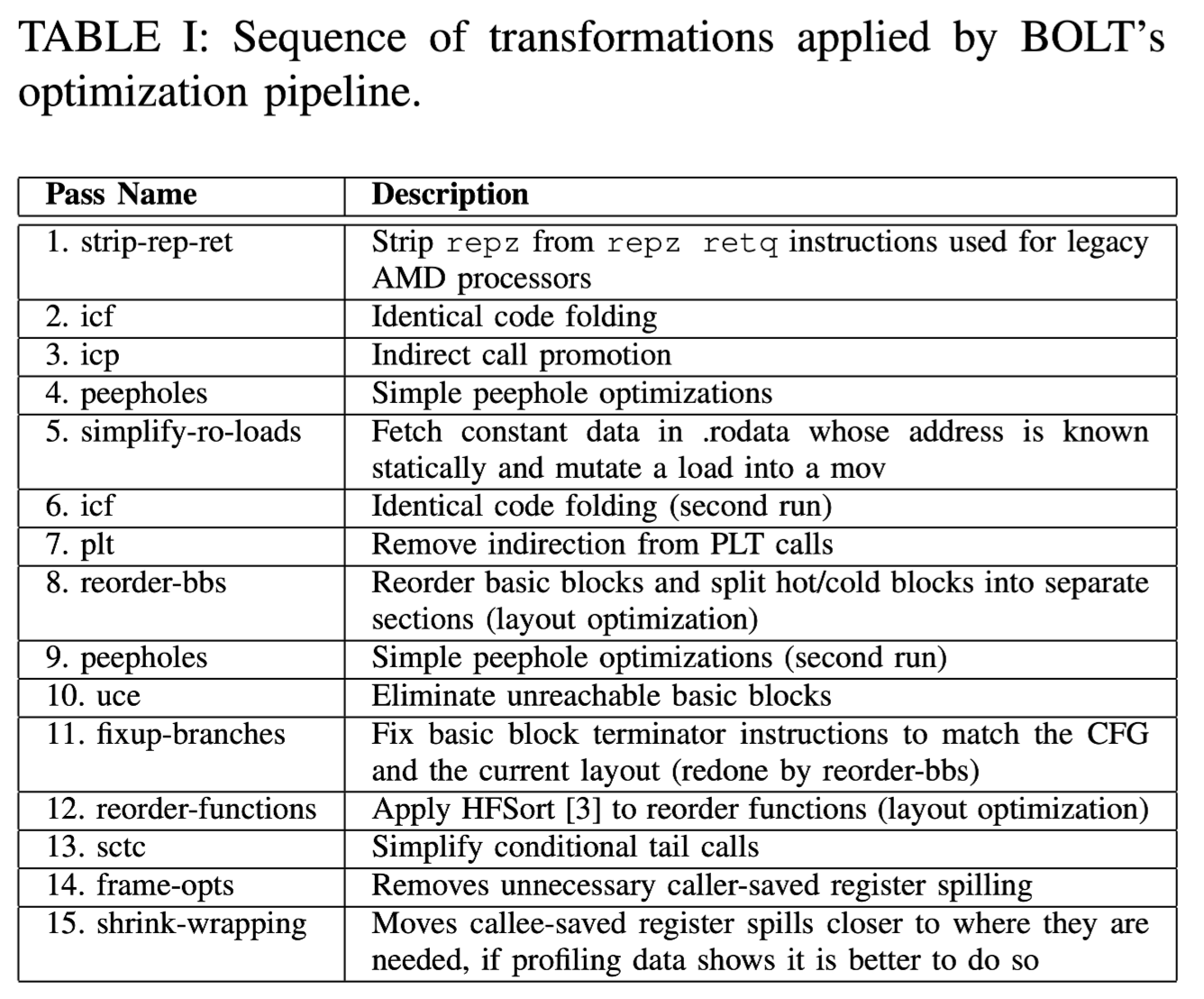
pass 就不展开介绍了:
- strip-rep-ret pass 是移除为解决一些 AMD 处理器分支预测问题,避免直接跳转到 ret 指令,而在前面添加的 repz 指令(repz 指令用在 ret 指令前面是无效的,而比起添加 nop 指令,这样做能节省解码带宽(decode bandwidth))。
- ICF 在之前的文章介绍过,是折叠相同实现的函数以减少二进制体积。
- ICP(indirect call promotion) 和 PLT call optimization 是根据调用频率信息来优化函数。
- simplify-ro-loads 权衡从 read-only sections 中获取数据的消耗。把取内存数据操作转换成常量编码进指令当中。 - reorder-bbs 是根据执行路径的频率来重排和划分 basic block,减少分支跳转和 CPU 分支预测的压力。
- reorder-functions 会使用 HFSort 技术重排函数,结合 peephole optimization(窥孔优化,一种对一小组编译器生成的指令执行的优化技术),可以直接优化代码布局,提升 I-TLB 和 I-cache 性能。
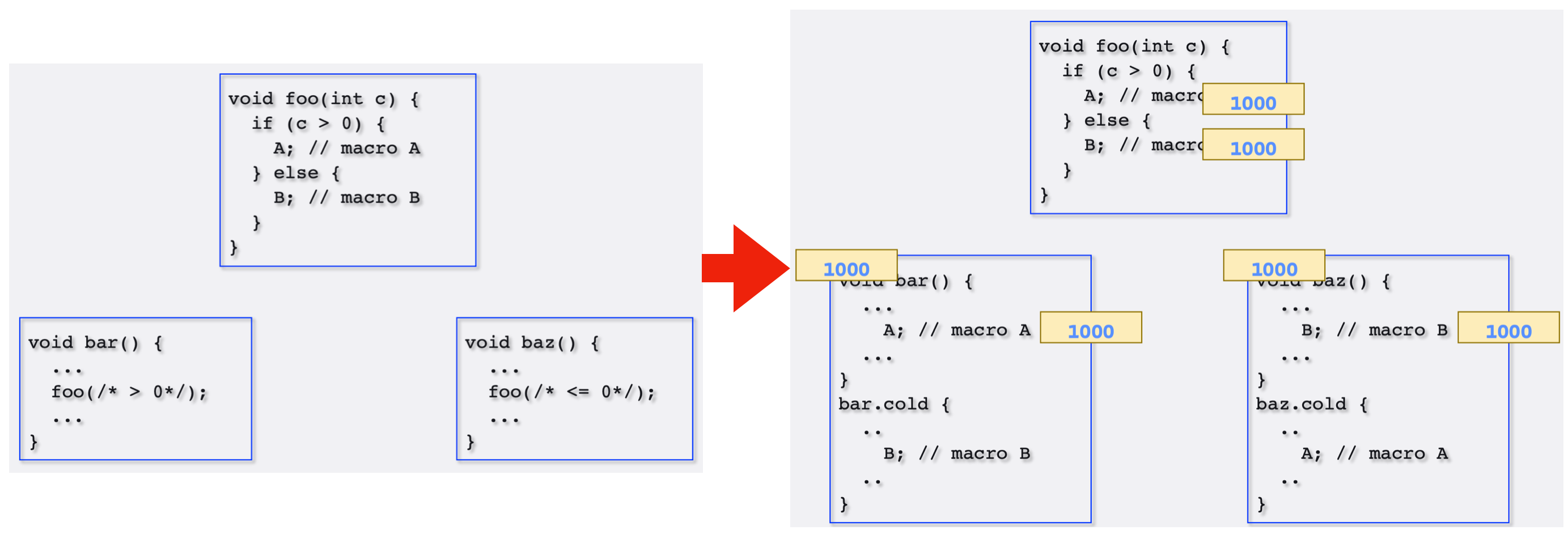
BOLT 在一个进程当中完成反汇编、优化、重写二进制的操作,所以它存在一些问题:无法有效利用分布式编译系统、重写 ~300MB 的代码段可能需要 70G 的内存和长达 10 分钟的时间。
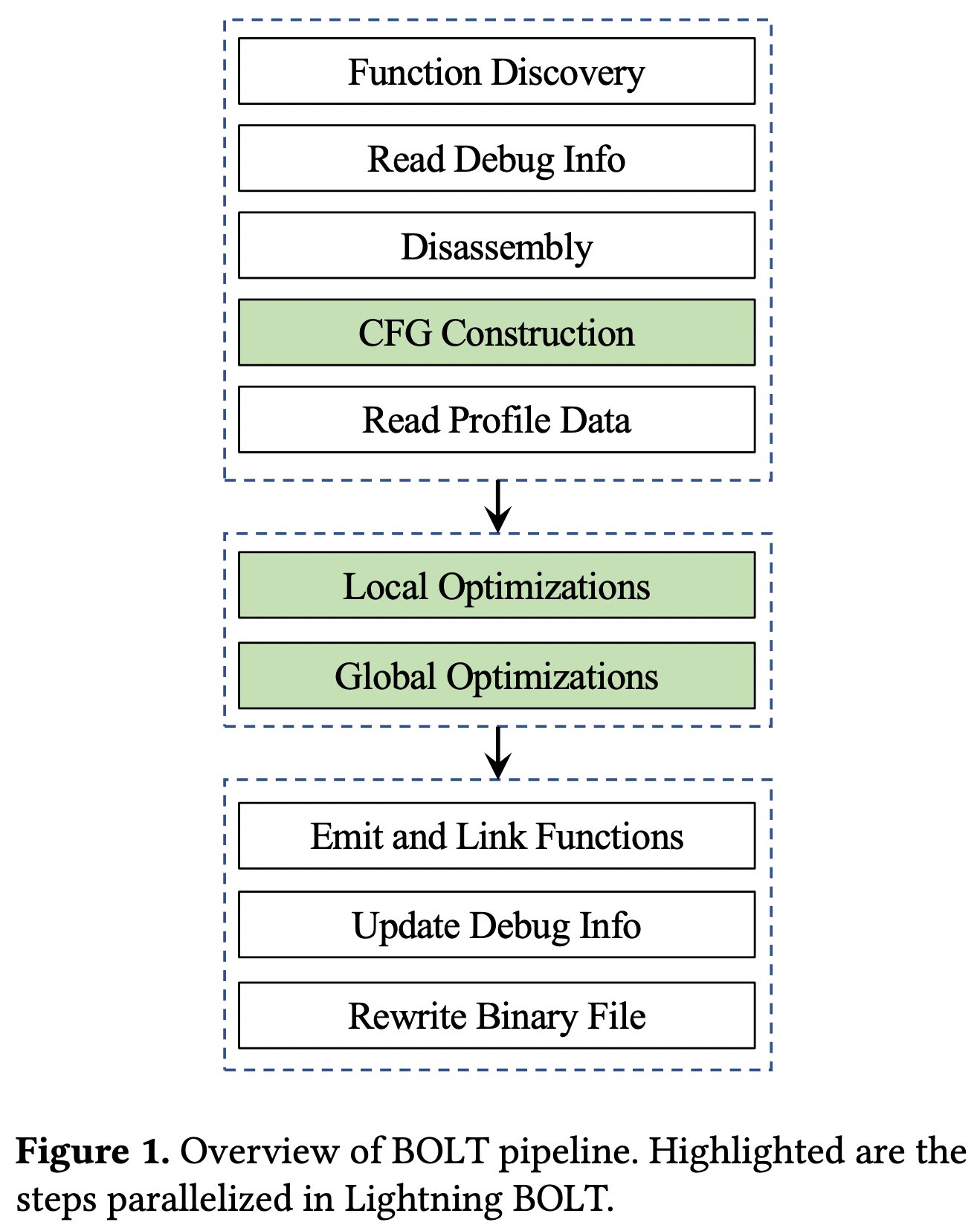
Lightning BOLT 就是把一些操作进行并行操作,如下图中标绿的部分。
而谷歌则是推出了 Propeller(Profile Guided Optimizing Large Scale LLVM-based Relinker),添加支持了链接器每一个 section 放一个 basic block,通过在链接期间基于 profile 信息进行整个程序的 basic block 重排、函数划分、函数重排,可以达到和 BOLT 几乎一样的效果。
- BOLT github
- BOLT llvm github
- BOLT: A Practical Binary Optimizer for Data Centers and Beyond
- Why is an empty function not just a return
- repz ret
- peephole optimization
- HHVM
- Lightning BOLT: Powerful, Fast, and Scalable Binary Optimization
- BOLT Open Projects
- Propeller
- Presentations/BOLT
- BOLT Video
- Accelerate large-scale applications with BOLT


